motivation.
this past spring, i taught <Fundamentals of Machine Learning> for computer science seniors (with some juniors as well as seniors from other majors, including data science and economics) at NYU. last time i taught this course, the course was titled <Introduction to Machine Learning>, it was pre-ChatGPT and it was pre-pandemic; in fact, i was teaching this course in the spring of 2020, and the whole university, city and world went into its first lock down mid-way. in other words, i taught this course in the old world, and i was asked to teach this course in this brave new world.
i did a quick informal survey (not necessarily only those students who enrolled in this particular course) before the semester began and learned that most of the students (computer science majors) had not tried out coding assistants (one way or another) until then, to my surprise. these are students who are graduating after this semester (and by the time i am writing this post, they effectively have,) and most of them will start their careers as software engineers or data engineers of some sort. indeed, it is not too difficult “if you know what you are doing” to familiarize yourself with these tools, but i have this strong conviction that we must provide environments in which these students make mistakes and learn from these mistakes while at school rather than doing so at work.
i thus decided to fully revamp the whole course with two goals in my mind. first, students will learn fundamental concepts from mathematics and statistics, necessary for machine learning, and what kind of machine learning algorithms they are realized into. but, i would not necessarily go deep into details about “how” they are realized. second, students would rather “feel” this process of going from fundamental concepts to concrete algorithms by building a full-blown software package (complete with backend, frontend, data ingestion and machine learning) from scratch for each and every machine learning concept i teach.
the latter is where magic of this new era (industrialized software engineering) enables us to do so, unlike the (resisting) old era (artisanal software engineering). instead of creating a relatively lame piece of a script implementing a toyish version of a machine learning algorithm, blanking out a few blocks here and there, and asking students to fill them in, we can now instruct students to build a full-blown app for each concept they learn, enabling them to directly touch and feel how mathematical concepts transform into concrete working pieces of software. yes, yes, it’s true that these cannot be commercially viable pieces of software (after all, they will have less than a few hours each week for this,) but compared to what i was able to do during my own undergrad years, we are truly in a brave new world.
so began the semester.
the first 2.5 weeks.
i spent the first two weeks (+ 1 little lecture on the first week of the semester which was only half) on teaching students mathematical and statistical foundations of machine learning. in a sense, these should have been already taught in prerequisite courses, but it is always a good idea to dig deeper into a small subset of these ideas that are most relevant to the actual content of this particular course. i covered the following topics:
- Vectors and vector spaces: instead of Euclidean vectors, i tried my best to present vectors as abstract objects that can encode almost anything we will deal with using machine learning.
- Random variables and probabilities: i tried to present a random variable as a vessel of uncertainty, trying to emphasize the necessity of embracing uncertainty in machine learning.
- Iterative optimization: i tried to entirely focus on convex optimization, and how many techniques from convex optimization can be made systematic (and eventually automated.)
as these lectures happen, in parallel, i’ve worked together with teaching assistants of the course (thank you!) to ensure that every student in the course has at least one (if not two to three) coding assistants on their laptop. furthermore, we spent quite a lot of time to ensure that they all get as many free credits and free accounts, often available to students in north america, in order for them to freely and also flexibly familiarize themselves with these tools. until march 15, microsoft github copilot and google ai pro were the best options for students with generous rate limits and free premium accounts. though, both of them have sunsetted these since then. openai now support $100 codex credits for students (thank you!) unfortunately, neither anthropic nor cursor has free student programs.
weekly vibe coding.
from thereon, the course entered the phase of learning and practicing machine learning at a weekly cadence. on monday, i (or some of the TA’s) spend 1h15m on teaching one particular concept in machine learning, after which i go back to my office and start vibe-coding a whole web app from scratch using a new dataset i never used before, showcasing this newly taught concept in machine learning. on wednesday, i come back for the other 1h15m-long lecture, open my laptop on the podium, beam up the screen and start going through the whole process of vibe-coding i went through myself since monday. it takes anywhere between 30m and 1 hour. i particular focus on how i set up the initial prompt (very painfully and carefully), what kind of mistakes coding agents made, how i noticed them and how i worked with coding agents to fix them. after this, i ask the students (both in person and over zoom) to open their laptops and start implementing this from scratch themselves.
a lot of students were pretty confused in the first week. as i roamed around the lecture hall looking students’ screens, i could see that most of the students were not sure what they should do. it was not easy to resist the temptation to handhold them step-by-step, but i resisted this urge. without such stage of confusion and agony, how would these students learn to familiarize themselves with new ways of work and study in the future?
here are the machine learning concepts and my own vibe-coded projects:
- Vector Space & Retrieval: similarity metrics (Cosine vs. Euclidean) and nearest neighbor search
- NYU Course Search (better than the official one!) https://github.com/kyunghyuncho/nyu-course-search
- Dimensionality Reduction: compressing and visualizing data & deep autoencoders
- NYU Yellow Cab Trip Visualization (using NYC Open Data) https://github.com/kyunghyuncho/nyc-taxi-trip-visualization
- Clustering: k-means clustering and mixture of gaussians
- Global Demographics & Economic Clustering: https://github.com/kyunghyuncho/clustering-countries
- Classification (LJ): Binary classification, multi-label classification and evaluation
- Lavender Jiang taught the Monday lecture.
- A Checker Bot: https://github.com/kyunghyuncho/checker-bot
- Regression & Uncertainty: Basic regression, mixture density networks and quantile regression
- Federal payroll prediction: https://github.com/kyunghyuncho/federal-payroll-prediction-antigravity
- Cross-Modal Retrieval: apping text/images to shared space using dual encoders & contrastive learning.
- Radhika Dua taught the Monday lecture.
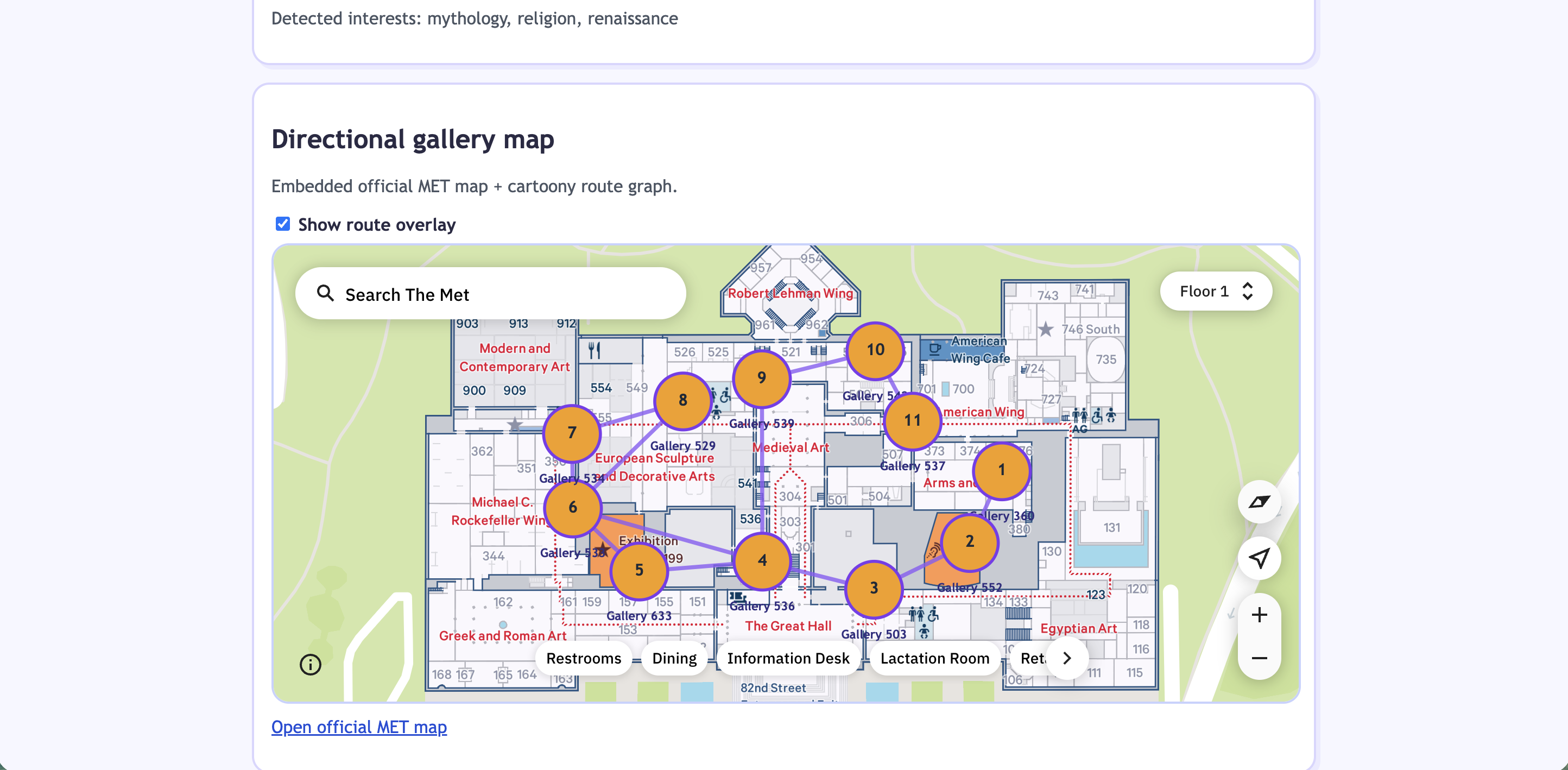
- Museum artifact retrieval: https://github.com/kyunghyuncho/the-met-retrieval
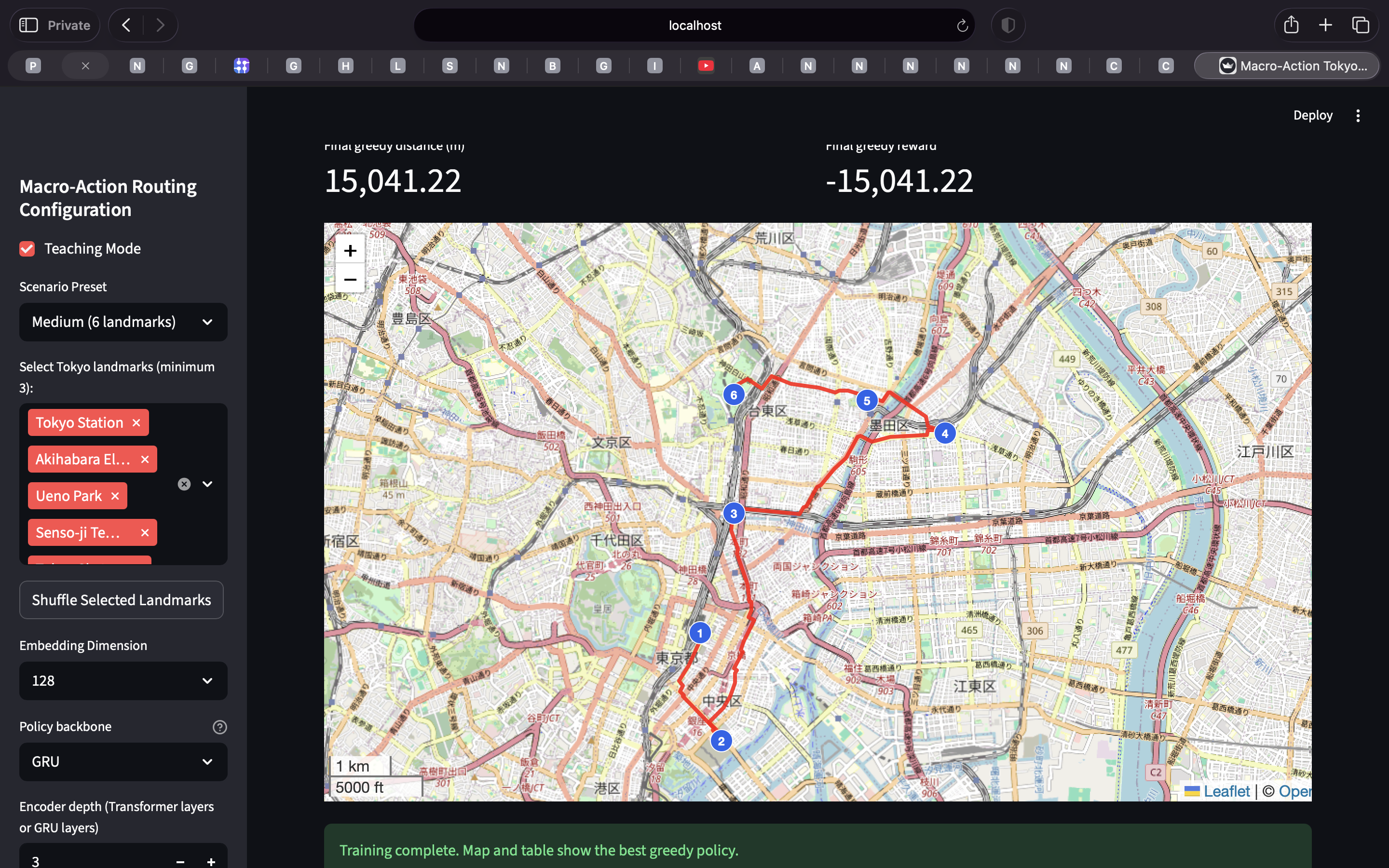
- Reinforcement Learning Basics: Agents, environments & rewards
- Stephanie Milani taught the Monday lecture.
- City tour routing: https://github.com/kyunghyuncho/manhattan-tour-route-cursor
there was one more lecture in which Bing Yan taught about generalization and evaluation. There was no separate vibe coding project for that particular week.
each week, after showing them what i created in front of the students, i’d post a few screenshots of my own app on campuswire (i’m a big fan of campuswire, although i can see how it is being less and less maintained … a bit sad) and encourage students to post screenshots of their own implementations. there was some significant lag between my post and students’ posting of their screenshots initially, but this lag dramatically decreased as the students became more familiar with machine learning as well as coding assistants of their choice.
here are a few screenshots from students. bear in mind that there was absolutely no base code provided to them but a quick explanation of my own endeavour:
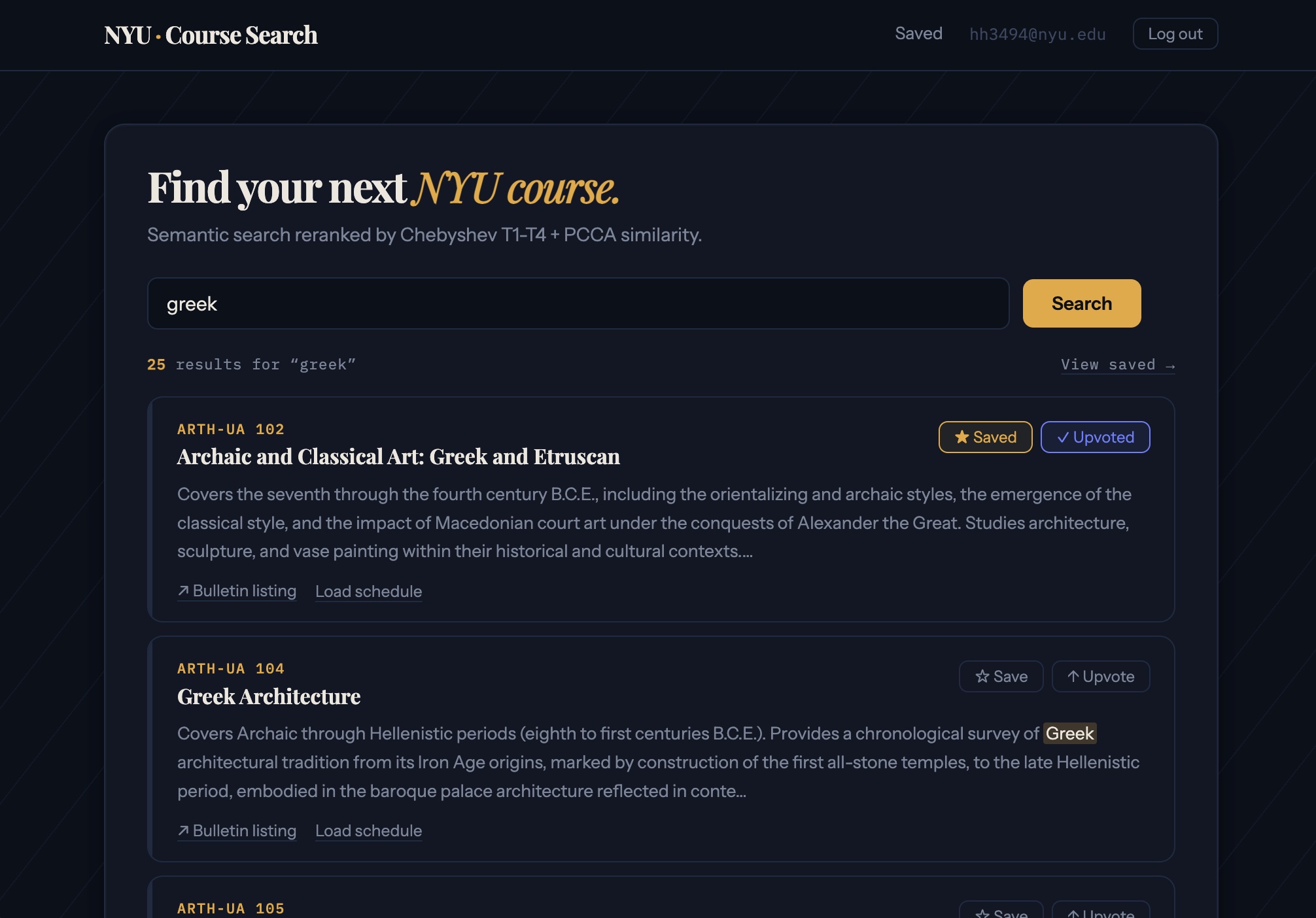
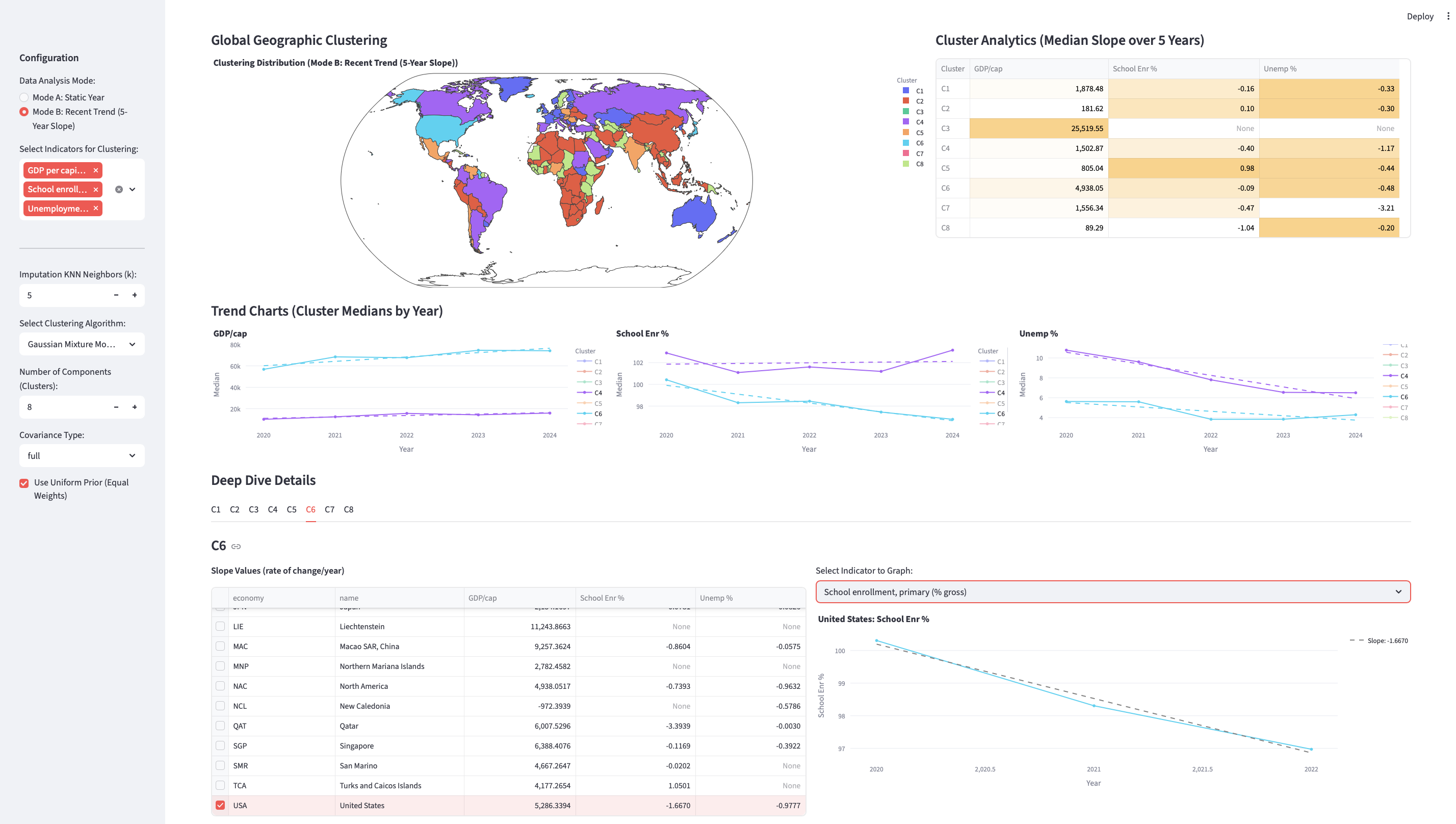
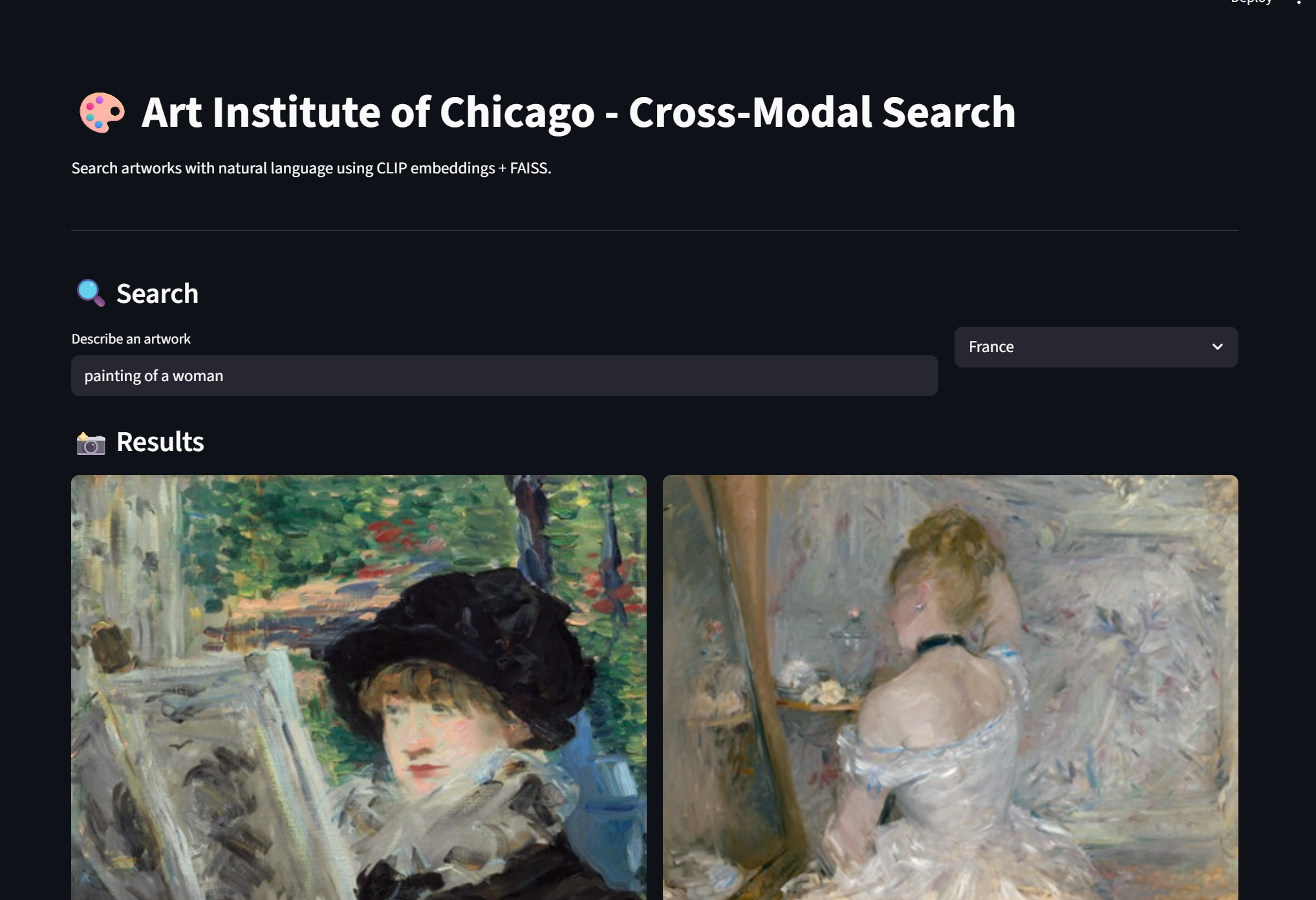
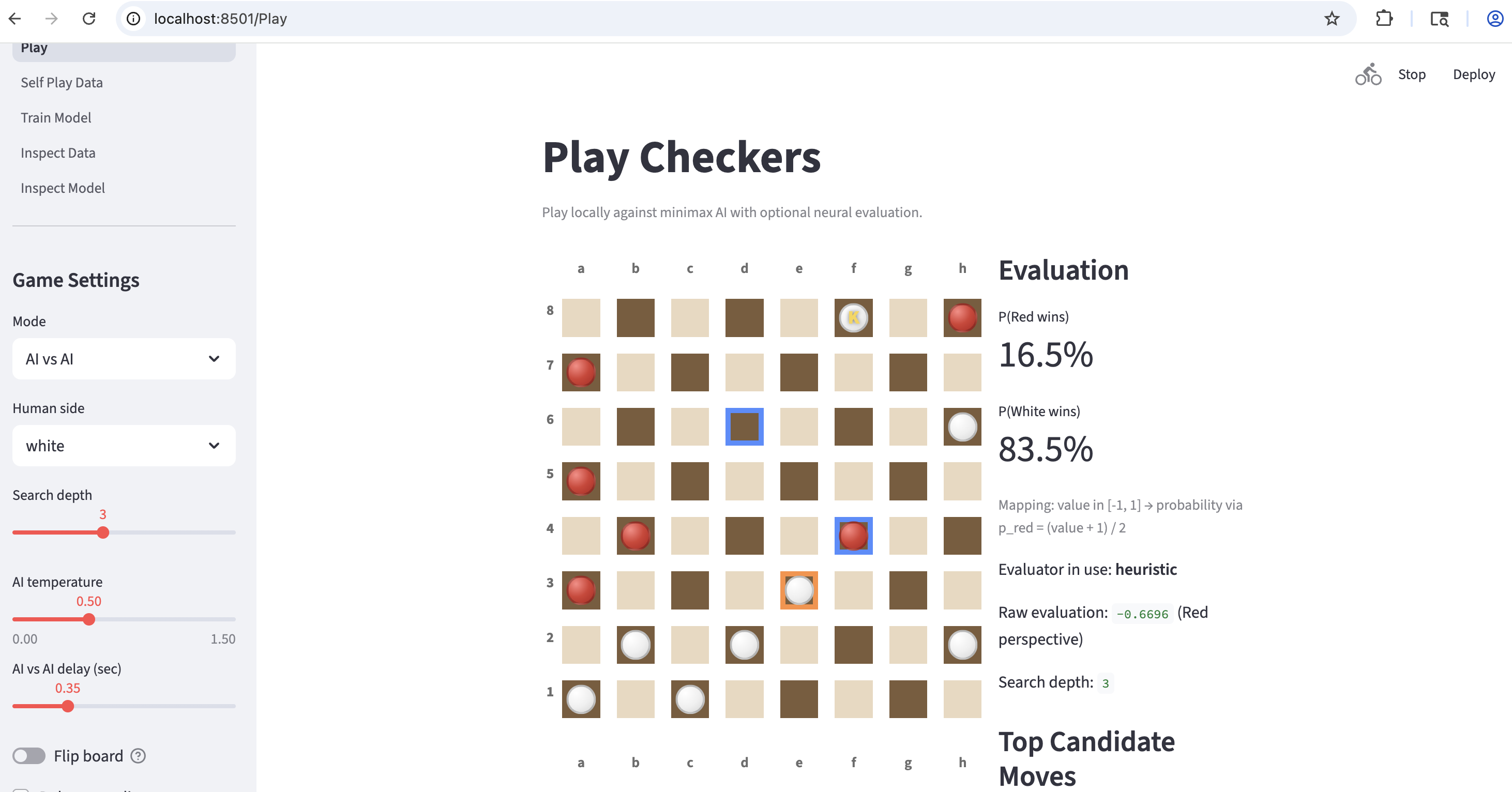
lab sessions.
these weekly lectures and vibe coding sessions were supplemented by lab sessions with more detailed descriptions and demonstrations of the effects of various aspects of these machine learning concepts. these lab sessions were created by and run by our absolutely fascinating instructors. in these lab sessions, we covered the following topics by showing them in programs how they work in detail:
- PyTorch basics: Vectors, inner products and random variables. taught by Lavender Jiang.
- Optimization. taught by Megan Richards.
- Transformers for embedding and efficient similarity search & indexing. taught by Ioana Marinescu.
- Creating reproducible, non-i.i.d. splits and analyzing distribution shifts. taught by Bing Yan.
- Training autoencoders & visualizing latent space. taught by Ioana Marinescu.
- k-means clustering. taught by Bing Yan.
- Training MLPs & evaluating F1 scores. taught by Radhika Dua.
- Quantile regression. taught by Michael Hu.
- Training a dual encoder on image-text pairs. taught by Radhika Dua.
- Simple RL experiment. taught by Michael Hu.
these sessions were designed by the TA’s to ensure that it is not just vibe-coding the students learn but also about the internal mechanisms by which these algorithms work. even then, we ensured each week at the weekly course meeting (happend at 9am every monday) that what we show is not a toy but a step toward the full-blown application in the future.
final projects.
similarly, final projects were designed to be mostly free of constraints or guidance. early on, a lot of students were confused and could not stop asking me about the rubrics for evaluation as well as my expectation on their final projects. my answers were always very simple: build what you want, build it really well and make sure it actually works. indeed, the most important criterion was for their apps to “work” when i tried them out myself on the podium after their 5-minute-long presentation.
over the full week of project presentation, each team presented their work for 5 minutes and then had their apps tried out by me on the spot on the podium in front of everyone. every single project started from scratch; there wasn’t even a rough idea set from which they could start. they really had to do everything themselves. the list of all projects are at the end of this post. my impression – simply “wow!”
the quality and diversity of the final projects really taught me a lot about teaching in this new era. we, educators, can now afford to not handhold students every single step but can show them goal posts that are far out and encourage them to reach them themselves. in doing so, they will not only learn knowledge but also build up experiences and hone their creativity, unlike how we were educated. what a truly blessed era for teaching and learning!
final words.
we are truly in the new era of learning and teaching; that is, education. it is tempting to dismiss this new trend by prematurely declaring what and how students should learn. it is premature, because these conventional ways of what and how are often not objectively optimal but simply the reflection of how we learned ourselves (plus just a bit of spices here and there.) i believe we have our own obligation to the society and in particular coming generations of students, to embrace and revise how we approach education and how we prepare our students for the society that is and will continue to go through a series of disruptions over the next few years and decades.
that said, i’m very optimistic after teaching this course. the students were amazing; they were able to follow me all the way through the course despite the apparent inexperience i could not hide myself (because i never taught any course in this way before.) in fact, at some point, i believe the students started to learn more themselves than what i was able to teach them myself. it is truly a new and brave world we are entering, and i’m extremely excited myself and for all students.
the list of final projects.
please reach out to me for introduction to students if you find any topic to be interesting and relevant.
- Music Discovery Engine — Recommends or surfaces music tailored to user taste. Team: Kai Banda, Sue Nan, Yanfu Wang, Aiden Cho, Max Tang
- Training Loop — Presents a project centered on the ML training lifecycle. Team: Isaiah Leong, Preston Delgadillo, Wenjie Zhang, Afomiya Yimenu, James Huang
- Met Museum Self-Tour Curator — Builds curated self-guided tours of the Metropolitan Museum. Team: Jason Liu, Zan Zhang, Tomas Gutierrez, Maymani Adhiphandhuamphai, Jessica Lee
- AniSync — Anime-focused discovery or synchronization tool. Team: Jack Xiong, Edward Kim, Jakob Rees, Vincent Wang, Tony Dong
- NBA Prop Forecasting: Pipeline & Model Architecture — Forecasts NBA player props with an explicit modeling pipeline. Team: Ishaan Sharma, Sharon Jiang, Kamran Hussain, Devlin Corrigan, Mina Ban
- Scholar: A Scholar’s Notebook — Notebook-style assistant for scholarly reading and notes. Team: Kevin Dong, Ian Tang, Kevin Pei, Xan Carey, Vivek Kondapalli
- Spotify Mood Playlist Generator — Generates Spotify playlists from inferred mood. Team: Gangwon Suh, Enoch Wang, Majo Salgado Quintero, Jonathan LaPoint, Shi Cheng
- Let’s Vibe Cook! — Recipe or cooking discovery aligned with a “vibe” or preference profile. Team: Louis Chang, Anchi Lin, Adithya Chebrol, Jia Qi, Brian Lee
- NYC Restaurant Survival Guide — NYC restaurant guidance framed as survival-oriented recommendations. Team: Jaiden Xu, Ryan Han, Rahul Adusumalli, Hollan Yuan, Muqiao Tao
- Modeling Drift in Medical Data — Studies or models distribution drift in medical datasets. Team: Stella Lin, Quentin Liang, Ryan Bi, Terrence Lin, Ethan Xu
- Calm Lions — final project — Course final project (on-slide title only). Team: Mia Li, Hanzhe Jiang, Thomas Wang, Ringo Chen, Yuyang Hu
- THE LOCAL MINIMA: Real Time News Narrative Analytics — Real-time analytics of news narratives. Team: Terence Xu, Mohamed Alremeithi, Kevin Ding, Wayne Zhang, Haokai Ma
- NYC Safe Restaurant Finder — Finds NYC restaurants with a safety-oriented lens. Team: Lisa Popova, Wendy Liu, Yixuan Du, George Liu, Yuxi Wu
- Cephalo: What is the impact of research paper embeddings on search effectiveness? — Evaluates how paper embeddings change search quality. Team: Benny Yuan, Massimo Daul, Moses Escarment, Andrew Jiang, Rushil Johal
- Multi-Objective Housing Recommender — Recommends housing under multiple objectives. Team: Weijun Wang, Shivi Pandey, Srivar Janna, Alex Muzila, Yingru Zhao
- Beyond Star Ratings: A Context-Aware Restaurant Recommender for NYC — NYC restaurant recommendations using context beyond star ratings. Team: Ashley Ying, Yoonjae Andrew Joung, Jacob Lipner, Langyue Zhao, Yiduo Lu
- ReadRadar: Semantic Book Discovery System — Semantic search and discovery for books. Team: Yizhen Yang, Benji Hua, Bruce Wang, Jiaqi Zhu, Krystal Wu
- Diet Twin Planner — Meal or diet planning with a “twin” or matched-profile idea. Team: Gaohong Chen, Boren Zheng, Jiahao Wang, Mingyuan Xia, Ben Kim
- Spotify Recommender — Recommends Spotify tracks or playlists via learned models. Team: Kevin Huang, Derik Zhu, Ritsuka Ting, Kevin Bu, Nicole Jin
- Music Semantic Recommender — Recommends music using semantic similarity beyond surface metadata. Team: Leo Li, Angela Gu, Jennifer Ran, Michael Wang, Huajie Zeng
- Steam Game Discovery: A Hybrid NLP and Vector Search Approach — Hybrid NLP and vector search for discovering Steam games. Team: Kylie Lin, Peter Miao, Zipei He, Weiyi Lu, Pearson Huang
- FlowTune: A Sequential Music Recommender for Dynamic Playlist Generation — Sequential recommender for evolving playlists. Team: Jack chen, Yihao Xing, Harrison Gao, Joe Song, Jiayi Hao
- Medical Insurance Cost Predictor — Predicts medical insurance costs from features. Team: Andrew Liu, Ben Ronen, Ruide Yin, Ruize Ma, Allison Zhu
- Kind Monkeys — final project — Course final project (on-slide title only). Team: Abel Ma, Rachel Ruan, Quinn Pu, Michelle Zhu, Emily Shi
- DineIntel: ML-Powered Dining Intelligence — ML-driven dining insights or recommendations. Team: Carolina Lee, Yihang Zhou, Yuxiang Bai, Ethan Demol, Yiwen Xu
- Beyond Keywords: A Semantic Restaurant Recommender — Semantic restaurant search going beyond keyword matching. Team: Andy Xu, Junting Wu, Akash Datla, Aurora Zhang, Olivia Yu
- League of Legends Team Drafter — Assists drafting League of Legends team compositions. Team: Jiayu Tang, Kaikai Du, ZhiHui Chen, Allison Tang, Rina Peng
- Recipe Discovery Web App — Web app for discovering recipes. Team: Aidan Ngai, Yige Zhou, Eddie Wu, David Wang, Jiaan Guo
- NYC Halal Restaurant Opportunity Finder — Maps opportunity or demand for halal restaurants in NYC. Team: Harsh Agarwal, Tony Zhao, Amanda Dong, Siqi Zhu, Catherine Yi
- Weather-ML: Find Your Perfect City Weather — Matches users to cities by preferred weather patterns. Team: Yarden Morad, David Hao, Vincent Qiu, Simon Ni, Eric Cheng
- A Multimodal Michelin Restaurant Discovery Engine for NYC — Multimodal search for Michelin-level dining in NYC. Team: Craig Nielsen, Grace Yin, Merry Ma, Zihe Liu, Zheyu Jin
- mcPHASES: P4 Wellness Platform — Wellness platform under the mcPHASES / P4 framing. Team: Kikki Liu, Tairan Lou, TB Rasya Danendra, Jade Lyu, May Zhang
- VibeMatch: Aesthetic-Driven Media Retrieval and Genre Classification — Retrieves media and classifies genre from aesthetic signals. Team: Bowen Tan, ZABIR MOSTOFA, Ethan Pan, Edoardo Mongardi, Owen Nie
- ResuMatch — Job–resume matching or ranking system (title only in metadata). Team: Alan He, Omer Hortig, Eliguli Han, Ryan Lu, Tanvi Patel
- 3D Hand Detection — Detects hands in 3D (vision / pose). Team: Cassandra Yang, Jean Park, Leo Qian, Sissi Hu, Suri Su
- VALORANT KILL PREDICTOR — Predicts kills or outcomes in VALORANT matches. Team: Ian Lu, Thomas Yanle Li, Shengyang Tao, Joseph Cheng, Alexandra Lugo
- Vibe-Check — Social or content “vibe” classification or scoring (title only in metadata). Team: Jinyu Zheng, Isabella Liu, Joseph Zhang, Yujia Guo, Zeyue Xu
- NearBite: Personalized NYC Restaurant Discovery — Personalized NYC restaurant recommendations. Team: Fidaa Abdulkareem, Albee Zhou, Jonas Chen, Yue Li, Nicholas Sidoti
- CineMatch: Your Ultra-Personalized Movie recommendation system — Highly personalized movie recommendations. Team: Giuseppe Aprile Borriello, Linyi Huang, Vayun Malik, Kathy Lin, Kardelen Kalyon