if you’ve been following me on twitter (X), linkedin, bluesky, etc., over the past few months, you may have seen me doing some random vibe coding here and there. in particular, over the past three weeks, i’ve been spending a few hours each weekend to check whether vibe-coding is real and if it’s ready for an individual, non-professional engineer to launch a web app online, from scratch without using any existing app development platform. i’m writing this blog post to list out some of the services and tools i’ve used to create a web app, to share with those who are not experienced (just like i am) but are interested in developing and deploying an (web) app, thanks to advances in AI for coding (vibe coding forever!)
as an obligatory disclosure: this is purely for my personal hobby/curiosity and was done outside my employment at NYU as well as Genentech. vibe coding is truly enabling people to expand their knowledge, experience and curiosity with a limited amount of resources, time and dedication. i love it. so, let’s dive into it.
i am personally interested in how to improve healthcare using ever-improving technology. perhaps it was because i’ve been a patient for a variety of conditions, with the most serious one being the thyroid cancer a few years back (don’t worry! i’m doing perfectly fine: https://kyunghyuncho.me/sharing-some-good-news-and-some-bad-news/). these experiences have made me wonder about my own health, and i have MyChart app on my phone that i check once a while to see if there’s any information about me there from my latest visits.
but, it is pretty clear that these apps are not friendly to patients (or users, since healthy people should also keep track of their own medical records and health conditions.) this unfriendliness of these eletronic health record (EHR) apps isn’t really intentional on the part of the EHR vendors (or so i want to believe,) but i attribute it to the history. until recently where every record has become electronic, it was pretty rare for general public to be able to easily keep track of their own records, be them medical or not: paper records can be burned, soaked in water, or simply thrown away when people move. therefore, important records, such as medical records, were kept elsewhere, and often where associated services were provided, such as in clinics and hospitals. this made records kept and maintained better, but of course as a consequence, we (patients) have lost control over our own medical records. since we don’t have control over these records, the record keeping industry has been largely serving care providers and insurance companies, implying that their main goals are to serve them not to create easy-to-use and friendly user interfaces to patients. so, historical artifacts not mal-intentions.
at least legally, it has however become very clear and codified that we (patients) own our own medical records and that we must be able to request and receive them at our request. furthermore, most of the EHR vendors now follow a shared set of protocols (unfortunately, we are not at the level of having literally a single unified protocol for all, although we are getting close) and we can download and merge our medical records distributed across multiple clinics and hospitals (unfortunately, not yet across countries easily, which kinda sucks for expats/immigrants like myself.) in short, if you’re in US and have been to any clinics or hospitals that use reasonable reputable EHR vendors, such as Epic and AthenaHealth, you can download your own medical records directly from their (web) apps.
a few weeks ago, i spent one weekend to implement a native python version of an app that ingests these downloaded records (often in the forms of xml files) and lets me consult an LLM based on these records. the code is opensourced in https://github.com/kyunghyuncho/MyChartExplorer/tree/main/PythonVersion. this version focused a lot on whether i can build a data ingestion pipeline into sqlite3 database (since i planned to use it for my own local use case only) without having to learn about the xml schema too much. to do so, i used Google Gemini 2.5 Pro by uploading one of the many (100+) xml files of my own to gemini, and asking it to read it and devise both a database schema and ingestion code in python. this worked beautifully, and after just a couple of back and forth, i could write a code that reads these xml files, parse them and save important (but succinct) set of data into the database automatically. after this ingestion was done, it was pretty straightforward to ask Google Gemini to implement a tcl/tk based python app for querying Gemini to (1) generate a bunch of sql queries and (2) use the retrieved information to answer any question i had about myself and my health condition.
it worked! i never created a python app with an actual GUI but i could do the whole thing in two days. but, it was … kinda ugly. though, looking at it again, it has this 90’s professional vibe:
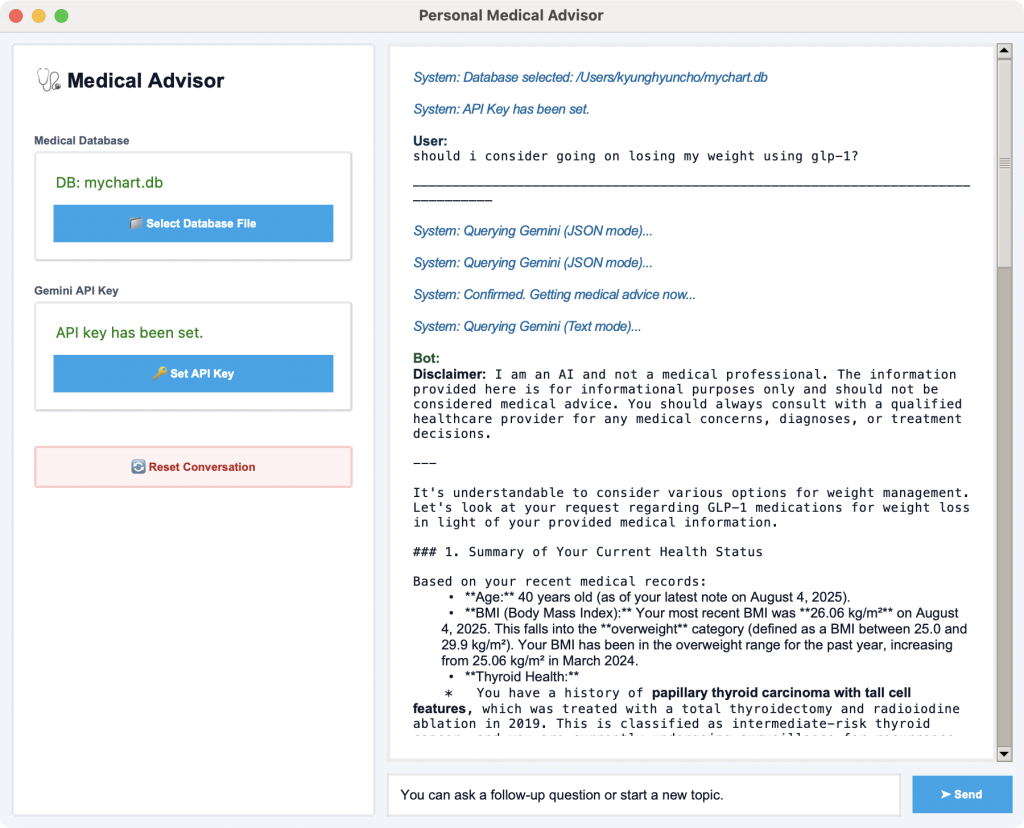
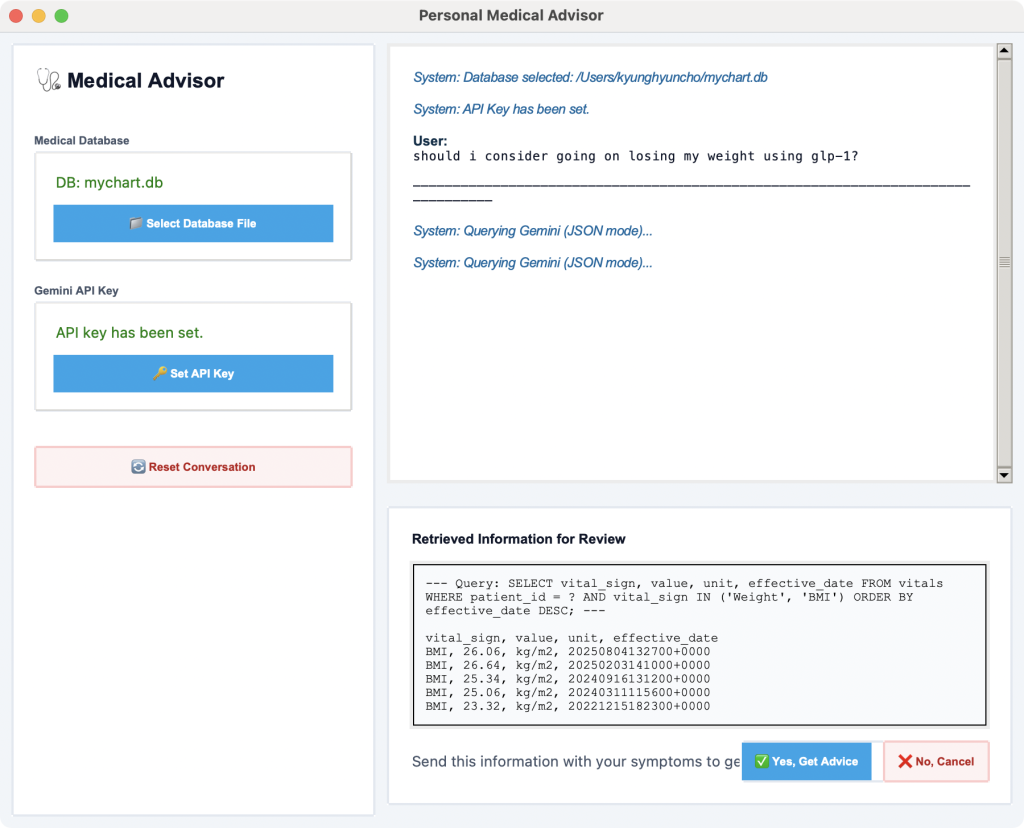
i then decided to port it to have a better UI. because i use mac, i decided to try to create a mac app version. i never built a mac app nor ios app, and i started by asking gemini what i should do. i just followed its instructions one step at a time and decided to go with Swift-based app. another hurdle, since i’ve never coded anything in swift nor even saw swift code before, but with LLM’s, nothing was going to stop me.
it was however a struggle, since gemini really sucked at getting details correctly with swift. i then had to switch back and forth between gemini and gpt-5. i was using github copilot plug in with xcode, which was also another hell i had to endure. but, eventually, i was able to code it up mostly using gemini with gpt-5 fixing any remaining bugs (gpt-5 is sooooo much slower than gemini.) this looked more in line with other mac app’s, but didn’t really implement anything beyond the original python version, named “Personal Medical Advisor” (which is a pretty bad name.) i called this new mac app “GeminiMyChartExplorer” (which is still a pretty lame name.)
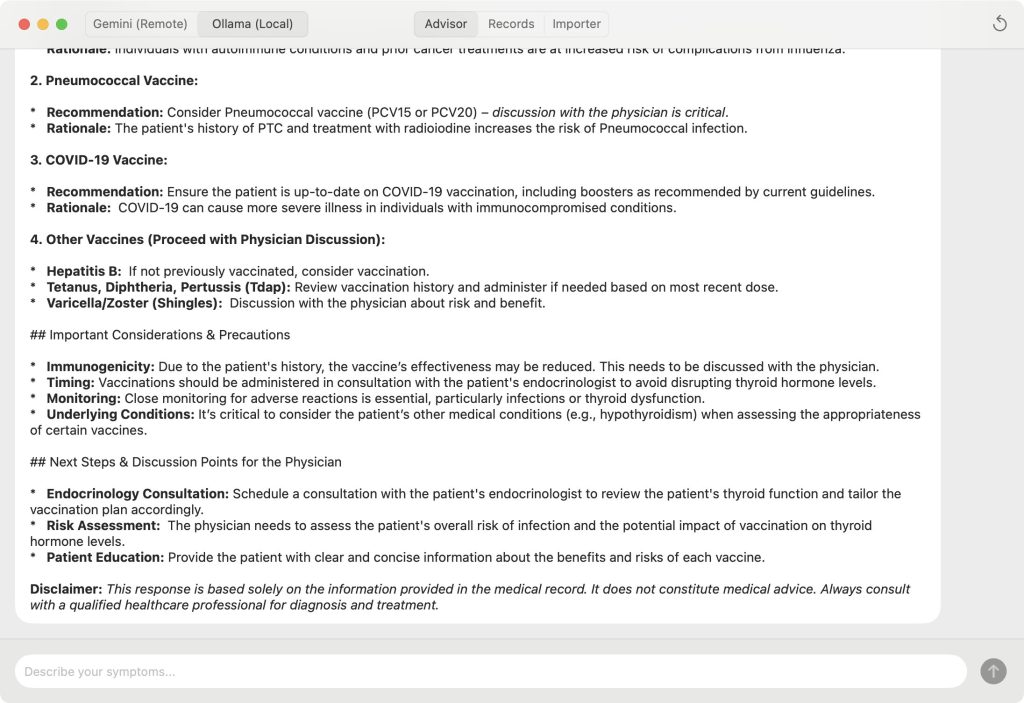
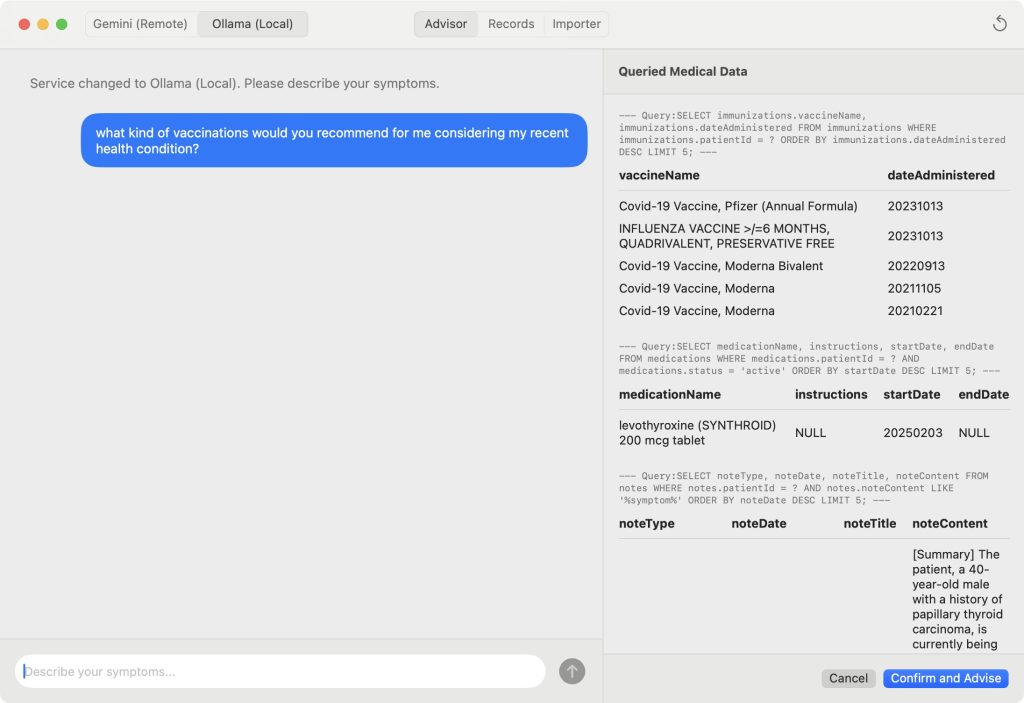
despite the name which contains “Gemini“, i also implemented using locally installed Ollama in this new version, as i started to get a bit more serious about supporting multiple back-end’s, although it was still all vibe-coded. this code was also opensourced in https://github.com/kyunghyuncho/MyChartExplorer/tree/main/GeminiMyChartExplorer. i’m super insecure about this app, however, since i still don’t know how to read nor write Swift. there could be a massive explosive bug in this code that will blow everything away, and i still couldn’t tell.
a few busy weeks passed by, and one weekend day, i woke up and realized the biggest issue of these local apps. if i were away from my laptop and had only a phone with me, i wouldn’t be able to access this app myself, since it is all local. i instead wanted a web app that i can access from any device i own directly.
so, i began another weekend of vibe coding. although i haven’t used it for development, i heard streamlit was one of the go-to choices for building a web app rapidly. i decided to give it a try by asking github copilot (using gpt-5 and gemini-2.5-pro back and forth) on vscode to port GeminiMyChartExplorer to a streamlit version. it was both a massive success (because i had more or less the perfected UI and framework immediately) and a massive failure (because neither gpt-5 nor gemini-2.5-pro could properly port the code without introducing non-existent features and accessing non-existent database tables, etc.) it took me sometime to go back and forth between the Swift implementation, which i don’t know how to read, and the streamlit implementation, with help from both gemini and gpt. eventually, i could get it running on my own laptop as a local service with all the features from GeminiMyChartExplorer intact.
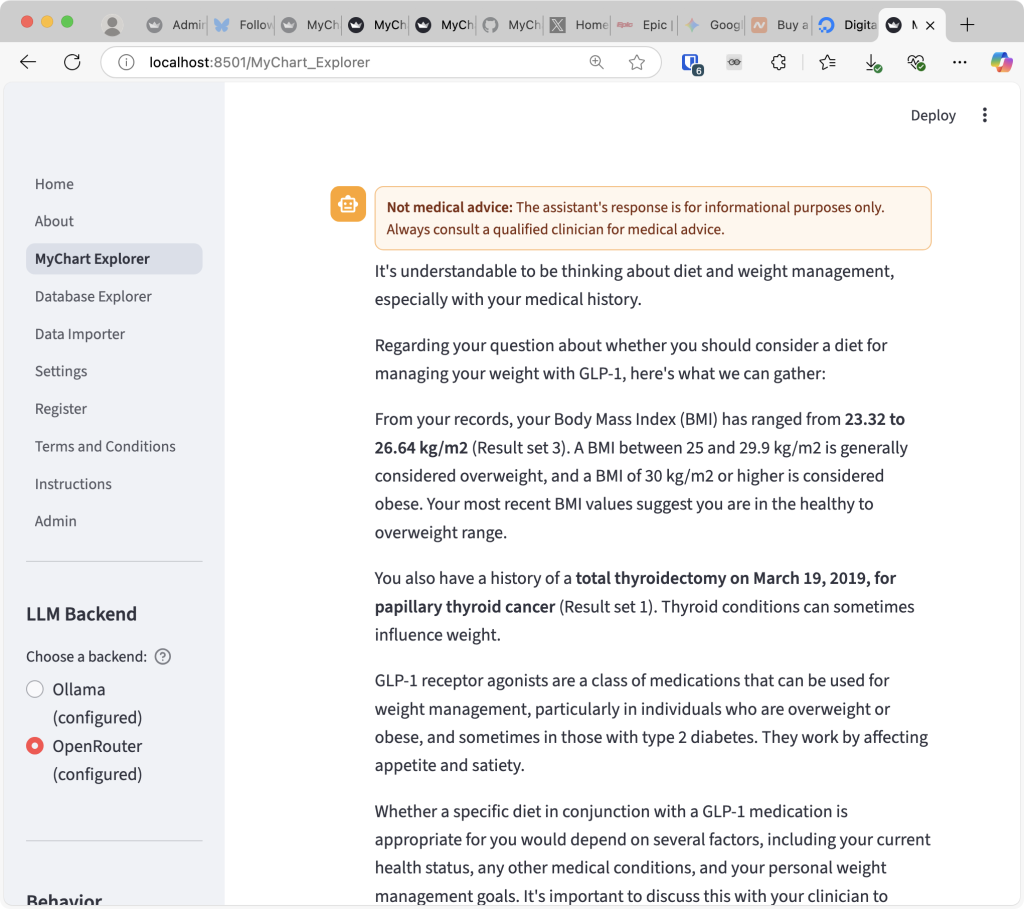
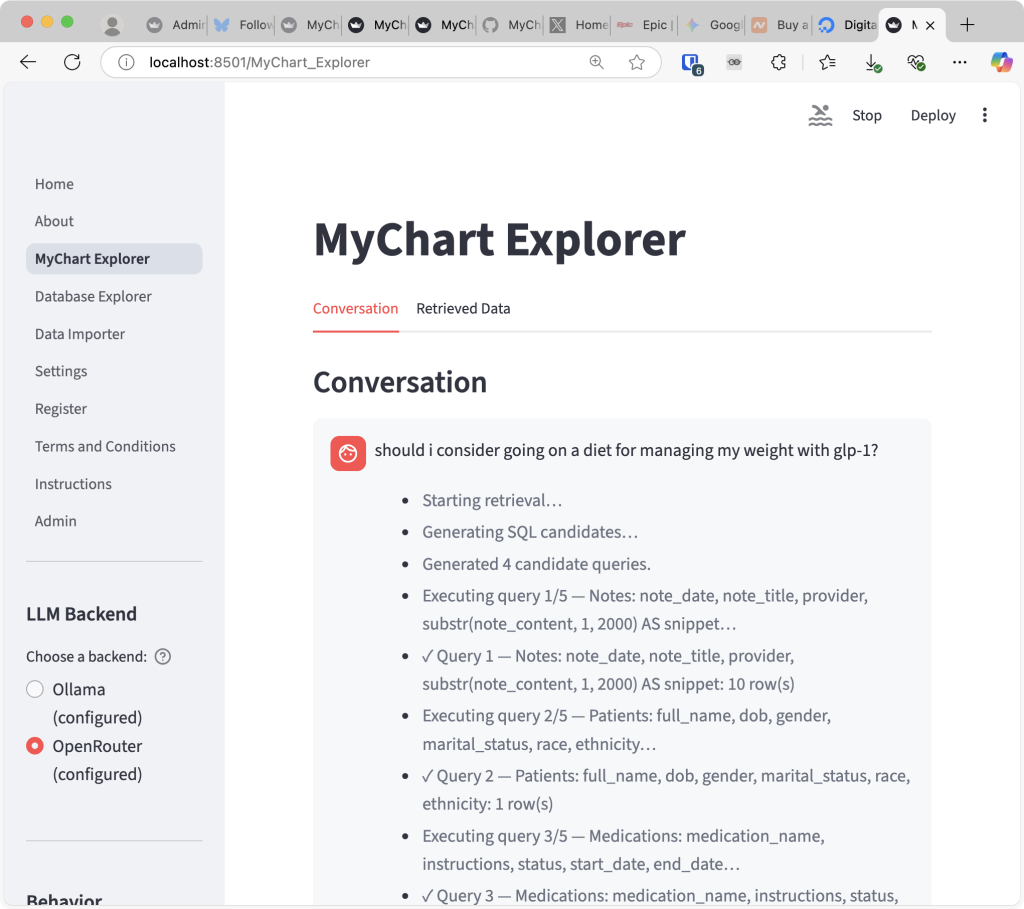
of course, running locally was just the beginning, since the whole reason i went down this rabbit hole was to set it up as a web service so that i can access it from anywhere. i decided to implement a few extra items before turning it into a web service: (1) encrypt the database as well as any saved conversation with an encryption key so that the records are stored securely (though, the strength depends on where the keys are stored,) (2) make it support multiple users (if it is a web service, why not make it usable by multiple users,) and (3) support ssh tunneling for an advanced user so that they can use their own version of llm instances. it took a few hours, but with help from gemini and gpt-5, i could implement them relatively quickly (obviously, it is gross oversimplification, and if you’re curious, check out the commit log of the repository, or don’t, since it’s a mess.)
finally, it was important for me to fiddle with the prompts as well as the UI so that it was very clear that the responses from the backend LLM are not medical advices and are only for informational purposes. this is important, since it is truly important for anyone who is concerned about their health to reach out to and talk with professional clinicians. i’ve seen all the troubling comments and articles online while i was looking for any consoling information when i was waiting for my total thyroidectomy and radioactive iodine therapy. the only information and advice that eventually matters for me were from consultation with doctors, nurses and technicians at the hospital.
then, i went into the rabbit hole of hosting this web service, now called MyChartExplorer.com. first, i bought mychartexplorer.com from Namecheap (which i’ve been using for years and also use for hosting this homepage.) i then went to DigitalOcean to buy the tiniest virtual private server (we used DigitalOcean 11 years ago to create our first attention-based neural machine translation demo.) i decided against getting a gpu instance, since i’m cheap, and make it into a bring-your-own-llm service. it was pretty straightforward to set up the dns on Namecheap to simply forward any traffic to the droplet on DigitalOcean, but then it hit me: it’s http, and everyone will see what i ask and any retrieved medical records.
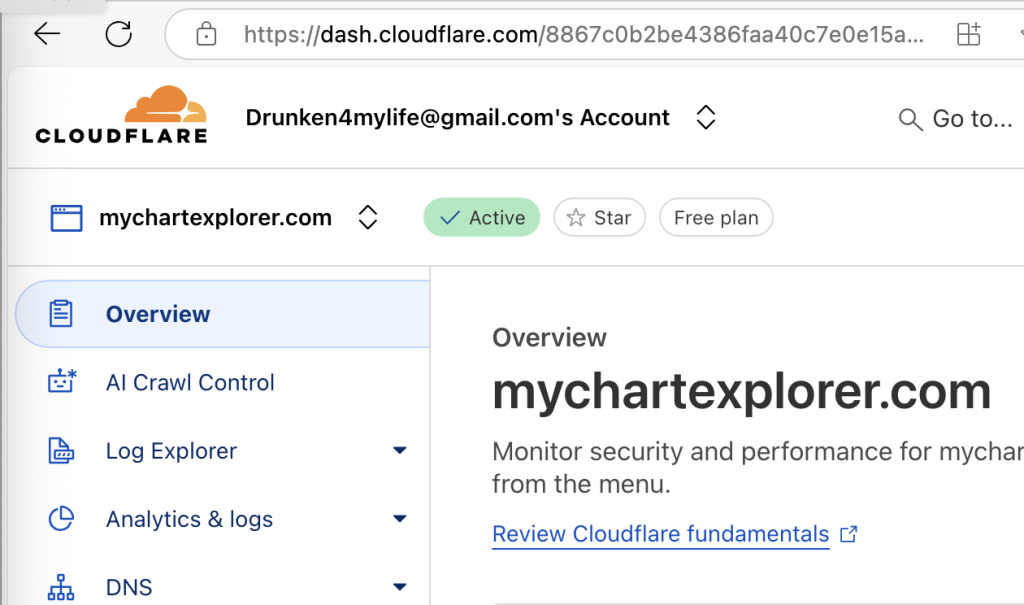
so, i decided to use https (as i’m doing so here on my homepage,) but again i’m cheap and lazy. in other words, i didn’t want to go through the rabbit hole of getting certificates, setting them up properly and maintining them annually. it’s already a hassle to do so for this homepage, and i wasn’t going to do so for my hobby project. instead, i decided to go with Cloudflare‘s origin server certificate option. this isn’t the best option, because it requires an enormous amount of trust on Cloudflare (cloudflare is essentially acting as a man in the middle here.) my laziness however won over my lack of trust this round, and i’ve set up cloudflare based https access to the droplet.

after everything was set up, i could try it myself by visiting https://www.mychartexplorer.com/. it was pretty smooth for me, and i was using Gemini with the API key i got from Google AI Studio. i then wanted my friends to try it out and set up invitation based registration. it turned out that we are not living in 2004 anymore and that we can’t simply run our own SMTP server with our own domain name, due to the lack of reputation (whatever that means.) i had to thereby look up some services and decided to give SendGrid a try (yet another API key to manage … ugh)
i then ran into two issues. first, no one wanted to download and upload their own medical records themselves manually. it’s both out of our inherent nature of laziness (because i do not like it myself either) and because we are not trained to do so; that is, to consider our own medical records as our own. in order to address this, i’ve decided to implement medical record ingestion via FHIR API from any Epic’s MyChart system, as Epic is the dominant player in the EHR market in US. it was painful … Epic’s documentation is pretty horrible (just like before, it isn’t in Epic’s interest nor historical momentum to support taking medical records out of their own system,) and it is actually pretty complicated. it took me about two weekend days to implement it, again thanks to the enormous amount of help from gemini and gpt-5. it worked beautifully on Epic’s sandbox.
unfortunately, when i tried to ingest my own records from NYU Langone, i learned that i need to get authorization from each and every hospital on the epic’s network for any user of these hospitals to use this feature to let MyChartExplorer ingest their data. as Josh Sato succinctly but precisely stated as a reply to my complaining tweet,

i pinged my colleague at NYU Langone, and the answer was pretty negative. of course, there are some good reasons. for instance, how would the hospital ensure that these app developers are not malicious and will leak patient data out? one could say that this can be dealt with by having severe penalty on these app developers, but once leaked, medical records are not something you can replace with new medical records. this level of security and paranoia is thus warranted, but it is indeed limiting. i’ve thus decided to leave the feature in place, with the hope that one day this feature will be used by me and any other user of MyChartExplorer.
the second issue was that non-developers don’t have Google Cloud account (to set up their Google Cloud project, set up billing therein and obtain their API key for gemini models) nor run their own Ollama server instance (duh… i don’t do that myself except on my own laptop.) this feels a lot like the mobile phone market in Korea during 90’s and early 2000’s, where you couldn’t get a mobile phone line unless you buy the phone together. that is, the phone and line were tightly coupled. you couldn’t bring your own line and use any phone you can buy on the market. you had to use the line that comes together with the phone. the current LLM-driven app market looks exactly like this: an app developer gets an API key from one of the vendors, embed it into the app and the user uses that particular backend via that particular api key to use this app.
i rather want to see the separation between LLM backend and apps, so that i can bring my own api key to the apps that i use. this will help me control my own use and also monitor my use in a single place. i complained about it on twitter, and thanks to jan harries, i realized that Openrouter comes close to this (although openrouter is still largely designed for developers not users):
i opened up MyChartExplorer, removed the gemini-specific code and implemented openrouter as a new backend. it is still bring-your-own-api-key, but it is specifically easier to create an API key on openrouter and add a credit to it than to create a google cloud account, set up a google cloud project and add billing to it (Google really needs to get their act together here):
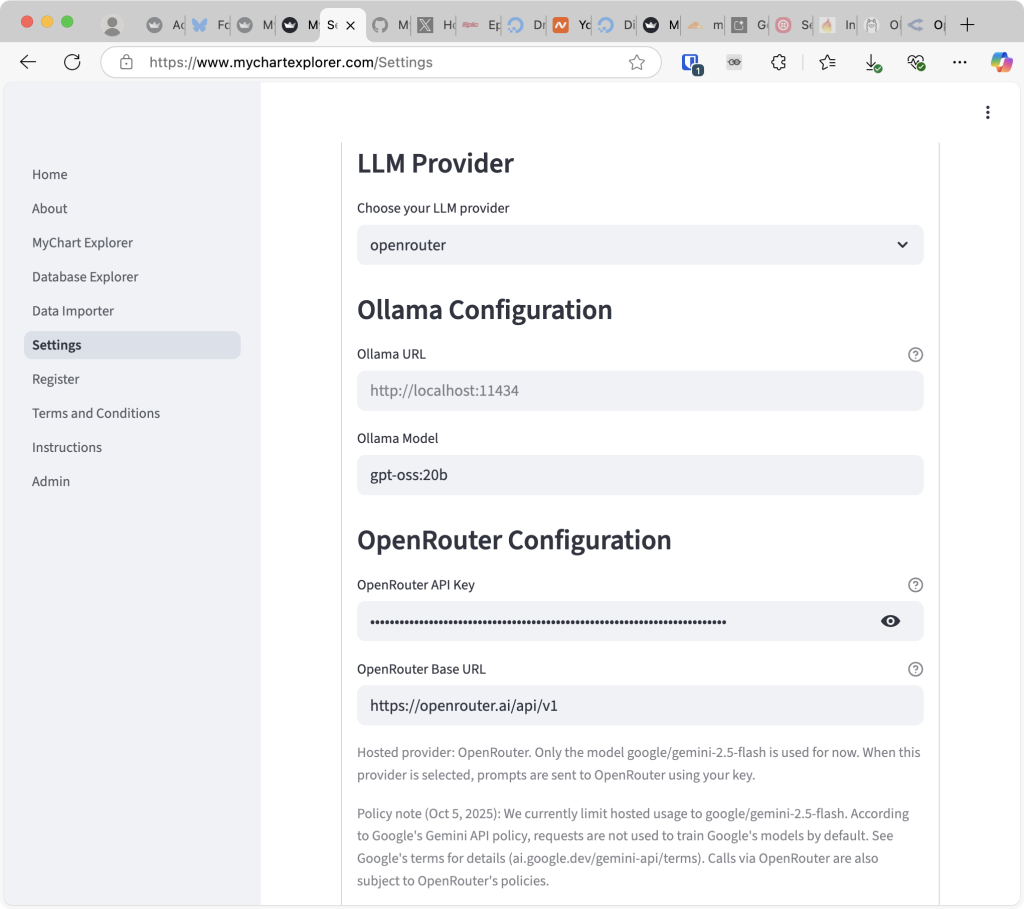
weirdly enough, gemini-2.5-flash is much faster and responsive via Openrouter than Gemini api. i wonder why? does Openrouter have a separate special lane bypassing some of those bloated code bases Gemini API has to go through? perhaps … regardless, their markup is then pretty reasonable, considering this speed up i noticed.
then i woke up one of these weekends and realized that i should be much more careful in opening this service up to more people. after all, medical records are indeed sensitive, and whatever care i put into protecting them, there could be unforeseen issues in the future. when that happens, i will of course take all possible actions to make it right, but i’m just an individual who has limited resources and time. or, more frankly, i started to worry that i myself might not be adequately protected (yes i’m a bit coward-ish in this sense.) i thus decided to create an LLC (limited liability company), pass this whole service to this LLC and let the LLC run it. it would’ve been much easier for me to use this service myself alone without worrying about it, but by that morning, i became too curious about creating an LLC myself (i tried to create a C corp earlier when i founded Prescient Design, but it was long ago and i was working with a law firm that did most of the actual work.)
i vaguely recalled hearing about LegalZoom from someone earlier and decided to look into LegalZoom. they made a pretty nice service where everything was done very smoothly (though, some of the service charge seem a bit steep.) once i chose to create an llc in NYS, i had to follow a few steps on their web site and put my credit card information. i did it before going to a gym in the morning, and by the time i was out of the gym, i was a proud member of KC Explorer LLC. that was … much quicker than i thought it would take. of course, i will try to make a business account at my bank sometime next week, but it was truly a rapid way to create an LLC. i then updated MyChartExplorer to reflect that this service is provided by KC Explorer LLC and also left a document stating that the domain name, source code and droplet have been transferred to KC Explorer LLC.
i don’t have any intention at this point to run this as an actual commercial service, since i don’t believe this could be a money-making service. to do so, it would require a lot more work to ensure the safety and privacy of patient information and also to work together with clinics and hospitals to maximize benefits to patients and minimize any harm. i plan to give access to this service to my friends who may be interested in exploring their own medical records with clear understanding that this is for their own informational use only and that this should not be used as medical advisory. of course, i can always ensure that those who understand these points get the invitations to the service.
that said, i believe this could be an interesting front-end interface for any patient coming to a clinic. instead of waiting for the next available appointment or in a waiting room indefinitely, the clinic would customize MyChartExplorer so that the patient converses with MyChartExplorer to describe their reasons for visit. this conversation, which is grouned on the patient’s medical records, will be summarized into a pre-visit report to be reviewed by the clinician who sees this patient. in this way, we can make each visit more efficient and thereby more effective. if any clinic/hospital is interested in this, i’m more than happy to chat with them about the potential. after all, i do believe we (everyone) have obligations to think of how to improve healthcare to maximize its reach and minimize any hurdle.
anyhow, this is what i did over the past few weekends, and this kinda wraps up my vibe-coding journey this time. feel free to reach out to me if you want to give it a try!